Rorschach Test as The First Human Classification Approach
Human personality classification. How, in principle, can one measure a complex and, in fact, unique human personality with a finite number of labels? Ascribe a human to one of a few categories? If it seems impossible to solve such a task, the human brain copes with it with a hurrah. We, actually, from the first moments of familiarizing with a new person can already write him down as a family man or a bachelor, a spendthrift or a miser, a careerist or an eternal student. How does this happen? It turns out that our brain loves and is able to simplify everything it encounters. By criterion brain knowns only, in the first 8 seconds, we can determine very precisely the social status of a person, whether he or she is in a relationship, whether we can trust him or her, etc.[1] It is as if we are labeling a person.
The first impression, of course, is not always the most correct and can change over time. But still, if the brain classifies people so effectively, can we find a scientific or pseudoscientific approach? Mankind made a lot of attempts in the past: signs of the zodiac in astrology, types of personalities in
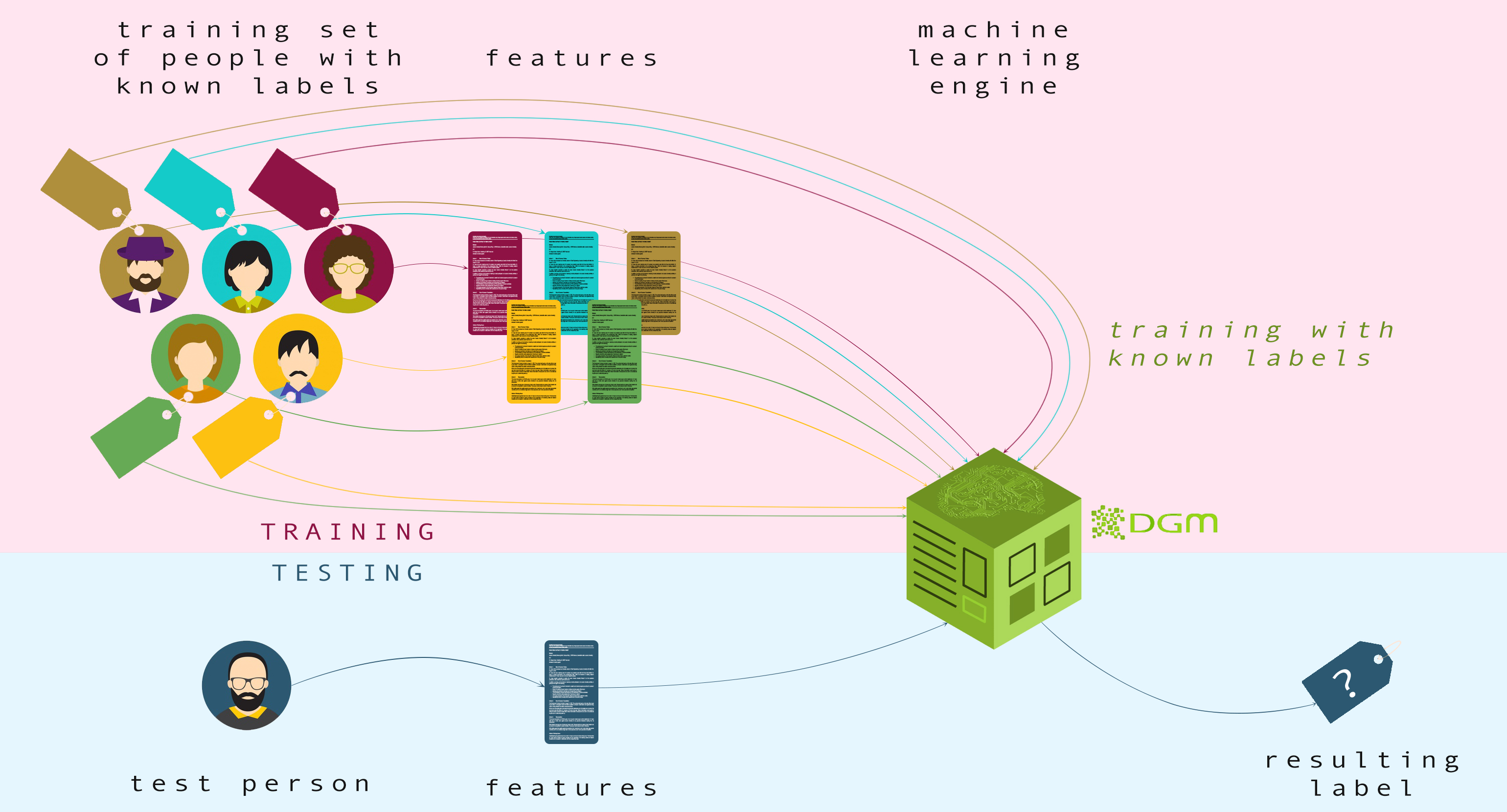
Feature Extraction
In machine learning we also preprocess the original input data to transform it into some new space of features where we hope, the classification problem will be easier to solve. The main idea of this preprocessing is to reduce the variability of input data for each class. This makes it much easier for a subsequent classification algorithm to distinguish between the different classes. We call this preprocessing stage feature extraction. Note that new test data must be preprocessed using the same steps as the training data. [2]
Thus, astrology uses only one feature – the date of birth. The archetypes of Carl Jung – two binary features: whether a test person relies more on intuition or sensation, thinking or feeling. Of course, Jung’s features are much more advanced than the ‘date of birth’ feature for classification. However, the first truly scientific method of classifying a person was proposed by Hermann Rorschach in 1921.
Rorschach Test
Look at this image. So it could be? An evil monster? A couple of friendly bears? For almost a century, 10 such ink spots have been used as a kind of mystical personality test.
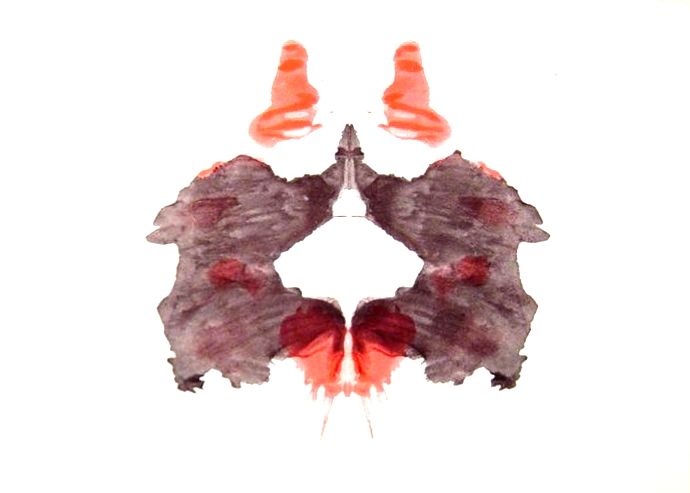
Developed at the beginning of the 20th century by psychologist Hermann Rorschach, the test is not really about the concrete things we see, but about our common approach to perception. As an amateur artist, Herman was fascinated by how visual perception varies from person to person. He transferred his passion for medicine and learned that our perception process not only registers sensory information but also transforms it. When he started working in a psychiatric hospital in Switzerland, he began to develop a series of bizarre paintings to gain a new understanding of this mysterious process. Using his ink-stained drawings, Rorschach began asking hundreds of people, the same question: “What can it be?”
However, for Rorschach was not really important what the subjects saw, but how they approached the task. What details of the image they were focusing on or ignoring. Whether they can see the movement on the cards. Did the color on some of the ink spots help to give a clearer answer or distract and crowd out the rest? Some people are inhibiting, giving the same answer for several spots, others give unusual and rich descriptions. The answers were as varied as the ink spots, offering different kinds of perception problems – some easier to interpret, others – harder.
Using Inkblots to Describe Human Personality
Rorschach developed a system to encode people’s responses, reducing a wide range of interpretations to a few average numbers. These numbers could serve as ideal features for modern machine learning engines (such as DGM library). But that time Rorschach himself acted as such engine – he had the empirical data to quantify all the tested people.
The analysis of the general approach of the tested person gives a real understanding of his personality and sychology. And as Rorschach tested more and more people, the number of models increased. Healthy subjects with similar personalities often used surprisingly similar approaches. Patients with the same mental illness are also similar in their responses, making the test a reliable diagnostic tool. It can also diagnose some conditions that are difficult to determine by other available methods. [3] Thus, the Rorschach test was the first scientific method for human personality classification
References
[1] J. Willis and A. Todorov Making Up Your Mind After a 100Ms Exposure to a Face. Psychological Science 17, 2006.
[2] S. Kosov Multi-Layer Conditional Random Fields for Revealing Unobserved Entities.
[3] D. Searls How does The Rorschach Inkblot Test Work? TED-Ed talk [video]












=frac{K_l}{K}")
=frac{1}{K}sum_i{frac{1_l}{(1+r_i-r)^2}},")