Sergey Kosov received his Diploma in Applied Mathematics from the Kirgiz-Russian Slavic University, Kirgyzstan in 2004, and M.Sc. degree in Computer Science from the Saarland University, Germany in 2008. From 2008 to 2013, he worked as a researcher in the Max Plank Institute for Informatics and Leibniz University, Germany. Currently he is an external Ph.D. student at Pattern Recognition Group in University of Siegen, Germany. His research interests include classification with conditional random fields and deep neural networks, motion estimation with optical flow, 3-D reconstruction as well as movie industry.
Right after Christmas OpenCV 3.4 update and before the New Year we are glad to present the latest and the greatest DGM 1.5.3: The library for Conditional Random Fields with OpenCV. This release includes three new classifiers:
OpenCV Artificial Neural Network
OpenCV k-Nearest Neighbors
OpenCV Support Vector Machine
and from now on uses unit-testing based on Google Test framework.
There is a wide variety of statistical models which may be applied to the semantic segmentation tasks. Let us now illustrate their impact on the computation of the label maps. For this purpose we use synthetic Green Field data-set, with 3 classes, described by two features. If we quantize all the features by 8 bit, we can map the whole data set to the 2-dimensional 256 x 256 feature space. If we accumulate the sample points in such representation, it will correspond to the probability densities. For the visualization we will mark these densities, belonging to different classes, with tree different colors: red, green and blue (see Figure below).
The original distributions of 160'000 samples from the dataset
Naïve Bayes model
Gaussian Model: the distribution is approximated with a single Gaussian per class
Sequential Gaussian Mixture Model
Gaussian Mixture Model, estimated with help of Expectation-Maximization algorithm
k-Nearest Neighbors classifier
Support Vector Machines classifier
Random Forest classifier
Artificial Neural Networks classifier
As we can observe from the Figure above, the generative models (Bayes and Gaussian mixtures) try to reproduce the original distributions. In order to do this precisely, a methods need to remember all the samples from the Green Field dataset – 160\’000 parameters. Or, in general, restricting ourself to the 8-bit features, a method needs to remember k·256^m values, where k is the number of categories and m is the number of features. The main idea of the generative models is to rebuild the original distribution using much less parameters and therefore generalize the model for samples, that were not observed during training. Bayes model approximates the distribution using only k·256·m parameters, and the Gaussian mixture model — k·G·m·(m +1) parameters, where G is the number of Gaussians in the mixture.
As opposed to the generative models, the discriminative models (Neural Networks, Random Forests, Support Vector Machines and k-Nearest neighbors) do not approximate the original distributions, but provide direct predictions for all testing samples. This grants the discriminative models more generalization power: In the areas, where hardly any training sample was met (left bottom and right top corners of the initial distribution image on Figure) all the generative models show black areas with almost zero potentials, while all the discriminative models how a high confidence about the class labels for these areas.
The release includes one new classifier (k-nearest neighbors) and now supports efficient calculation also on GPU. Moreover, the library now has DGMConfig.cmake files to be easily integrated in other projects with CMake.
The next version of the DGM library will make use of the fast parallel computing using Graphics Processing Units (GPU) of the graphics cards, supporting Direct X. The current version of the DGM library supports the Parallel Patterns Library (PPL), which allows for the parallel multi-core computing on Central Processing Unit (CPU). The Accelerated Massive Parallelism (AMP) library takes advantage of the data-parallel hardware that’s commonly present as a GPU on a discrete graphics card. Actually, the internal mechanisms of the AMP library may decide where to execute the C++ code: on CPU or GPU.
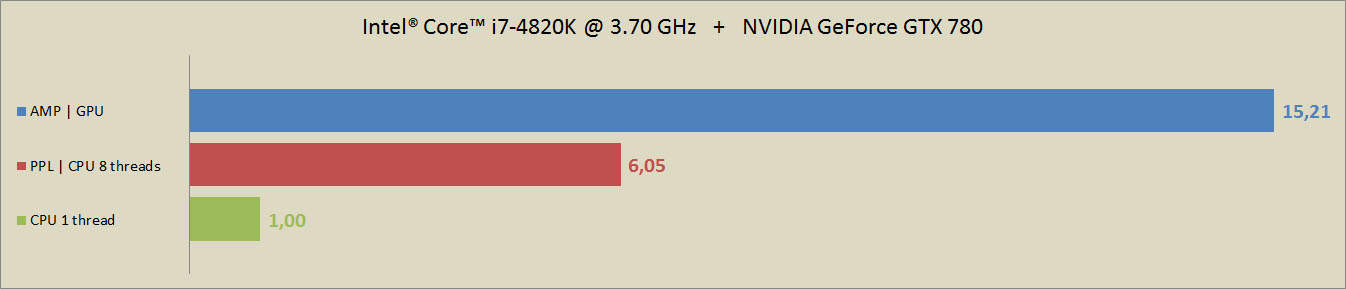
The speed-up, when using PPL and AMP libraries for the first system may be seen at the following figure:
here, 1,00 corresponds to the time needed for 2 iterations of the training algorithm (2 180 seconds). Accordingly, for the AMP | GPU this time is 15,21 times smaller (142 seconds)
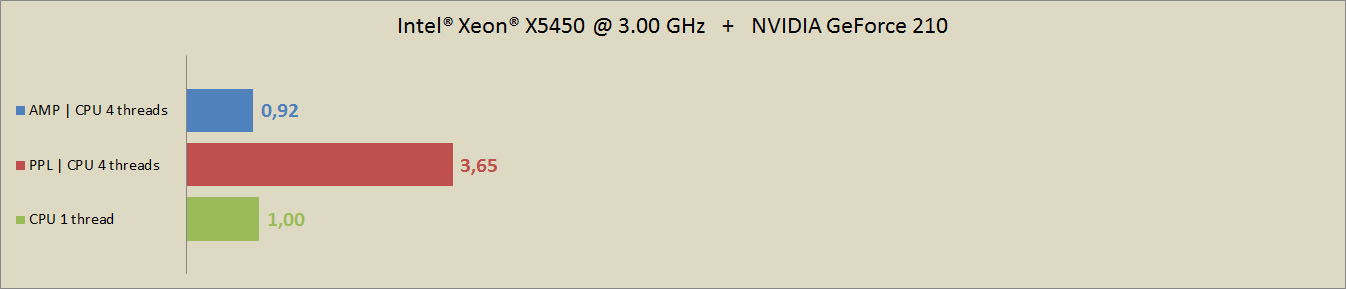
The speed-up, when using PPL and AMP libraries for the second system may be seen at the figure:
Here, the AMP library decided to run the code on CPU instead of GPU. This lead to significant performance drop. Again, 1,00 corresponds to the time needed for 2 iterations of the training algorithm (4 437 seconds on X5450). The parallel computing on CPU with the PPL library took 3,65 times less time and parallel computing on CPU with the AMP library took even more time – 4 819 seconds.
Instead of conclusion
On the systems with powerful graphics cards, please build the DGM library with the option ENABLE_AMP in CMake. Otherwise, please use only ENABLE_PPL option.
with tons of improvements and bug fixes. Among improvements one can find multi-layer graphical models, global features extraction, new 3D OpenGL graph viewer, etc. More details in the changelog.
We invite all developers to check out the code and contribute, join us on GitHub. Pull requests, issues, and library recommendations are more than welcome!
Project X Hyperlapse Stabilization is a technology that removes annoying shaky motion from videos and creates smooth and stabilized time lapses from image sequences. Video stabilization is an important video enhancement technology which is in great demand in timelapse and hyperlapse photography. We develop a practical and robust approach of video stabilization that produces stabilized videos with good visual quality.