The next version of the DGM library will make use of the fast parallel computing using Graphics Processing Units (GPU) of the graphics cards, supporting Direct X. The current version of the DGM library supports the Parallel Patterns Library (PPL), which allows for the parallel multi-core computing on Central Processing Unit (CPU). The Accelerated Massive Parallelism (AMP) library takes advantage of the data-parallel hardware that’s commonly present as a GPU on a discrete graphics card. Actually, the internal mechanisms of the AMP library may decide where to execute the C++ code: on CPU or GPU.
AMP VS PPL
We have made one performance test, using the task of the sparse coding dictionary learning. The bottleneck of this function is the algorithm, calculating the matrix product. Using the parallel implementation of this algorithm, we may achieve the sparse coding dictionary learning function with 90%-95% sequential processing. Our implementation of the matrix product may be found here.
Our test was performed using two systems:
- Intel® Core™ i7-4820K @ 3.70 GHz + NVIDIA GeForce GTX 780
- Intel® Xeon® X5450 @ 3.00 GHz + NVIDIA GeForce 210
The speed-up, when using PPL and AMP libraries for the first system may be seen at the following figure:
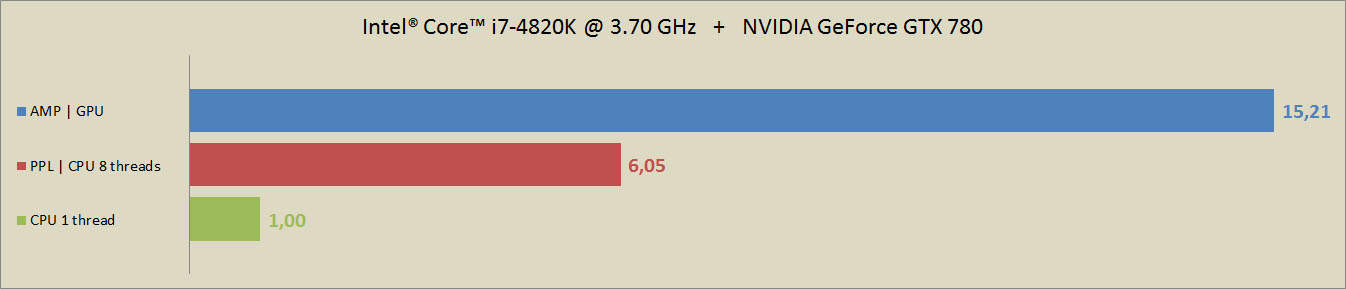
here, 1,00 corresponds to the time needed for 2 iterations of the training algorithm (2 180 seconds). Accordingly, for the AMP | GPU this time is 15,21 times smaller (142 seconds)
The speed-up, when using PPL and AMP libraries for the second system may be seen at the figure:
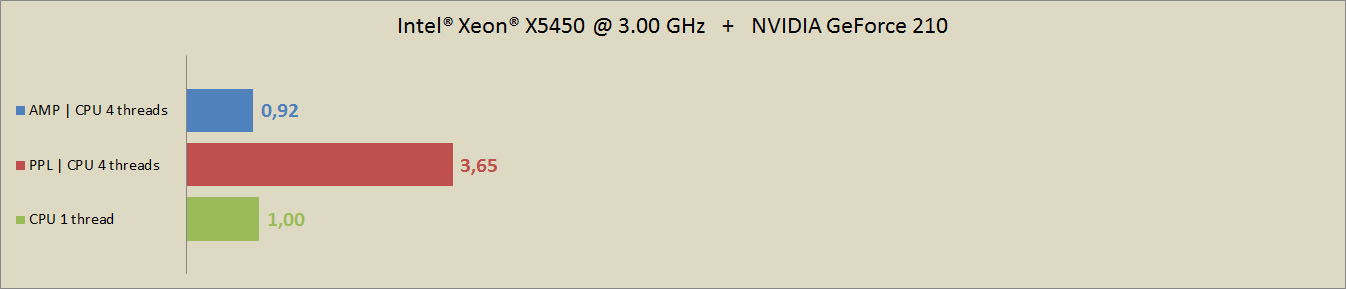
Here, the AMP library decided to run the code on CPU instead of GPU. This lead to significant performance drop. Again, 1,00 corresponds to the time needed for 2 iterations of the training algorithm (4 437 seconds on X5450). The parallel computing on CPU with the PPL library took 3,65 times less time and parallel computing on CPU with the AMP library took even more time – 4 819 seconds.
Instead of conclusion
On the systems with powerful graphics cards, please build the DGM library with the option ENABLE_AMP in CMake. Otherwise, please use only ENABLE_PPL option.


